Ever wondered how data architects conjure order from the chaos of raw information, transforming it into structured knowledge? The "create table" statement stands as a cornerstone of database management, the very command that breathes life into structured data repositories. Without it, databases would be formless voids, incapable of holding the insights we desperately seek.
The `create table` statement, in essence, provides the blueprint for a new table within an existing database. It meticulously defines the table's name, its columns, and the data types each column will accommodate. This foundational act of creation sets the stage for all subsequent data manipulation and analysis. Beyond the basic syntax, however, lies a world of options and considerations that can significantly impact the table's performance, storage, and overall utility. Different platforms, like Hive and Spark SQL, offer variations on the `create table` command, each with its own nuances and capabilities. Mastering these variations is crucial for anyone working with big data and distributed computing.
| Category | Information |
|---|---|
| General | |
| Name | Create Table Statement |
| Description | Defines a new table within an existing database. |
| Purpose | To structure and organize data for efficient storage and retrieval. |
| Technical Details | |
| Syntax | CREATE TABLE table_name (column1 datatype, column2 datatype, ...); |
| Variations | Hive, Spark SQL, SQL Server, MySQL, PostgreSQL |
| Key Attributes | Table name, column names, data types, constraints (e.g., primary key, foreign key) |
| Common Data Types | INT, VARCHAR, DATE, BOOLEAN, DECIMAL |
| Spark SQL Specifics | |
| Commands | Spark.sql("CREATE TABLE ..."), CREATE TABLE AS SELECT (CTAS) |
| Temporary Tables | CREATE OR REPLACE TEMP VIEW |
| Data Sources | Parquet, ORC, CSV, JSON |
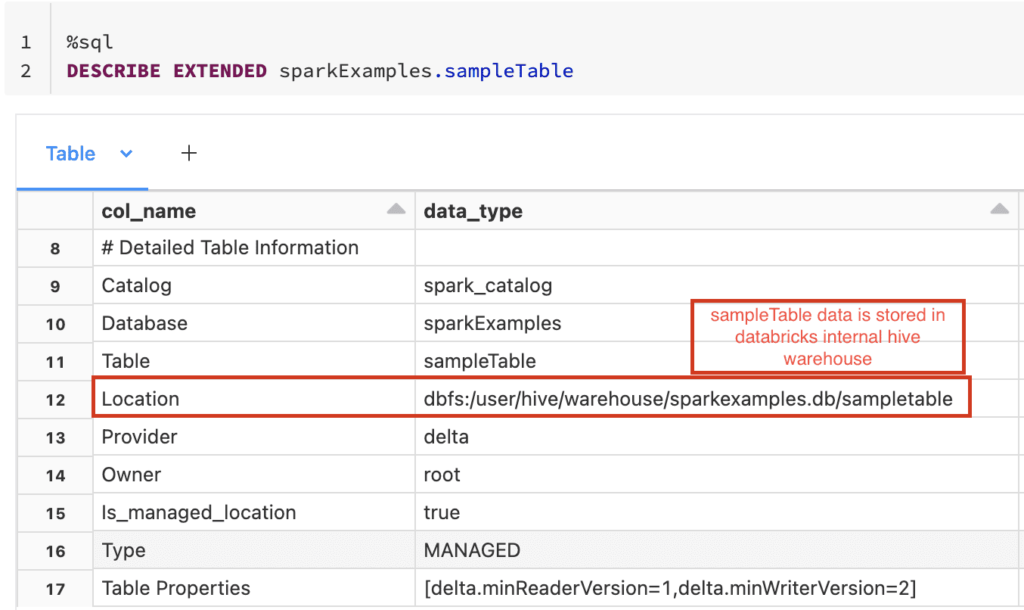
| Managed vs. External Tables | Determined by the presence of a 'LOCATION' clause. |
| Example | |
| Spark SQL Code | Spark.sql("CREATE TABLE IF NOT EXISTS mytable (id INT, name STRING)") |
| External Resources | Apache Spark SQL CREATE TABLE Documentation |
Consider the nuances of creating tables in Hive, a data warehouse system built on top of Hadoop. The `create table using hive format` statement hints at Hive's specific data storage and retrieval mechanisms. Hive tables often rely on formats like ORC or Parquet, optimized for efficient querying of large datasets. Understanding these formats and how they interact with the `create table` command is vital for optimizing data warehouse performance.
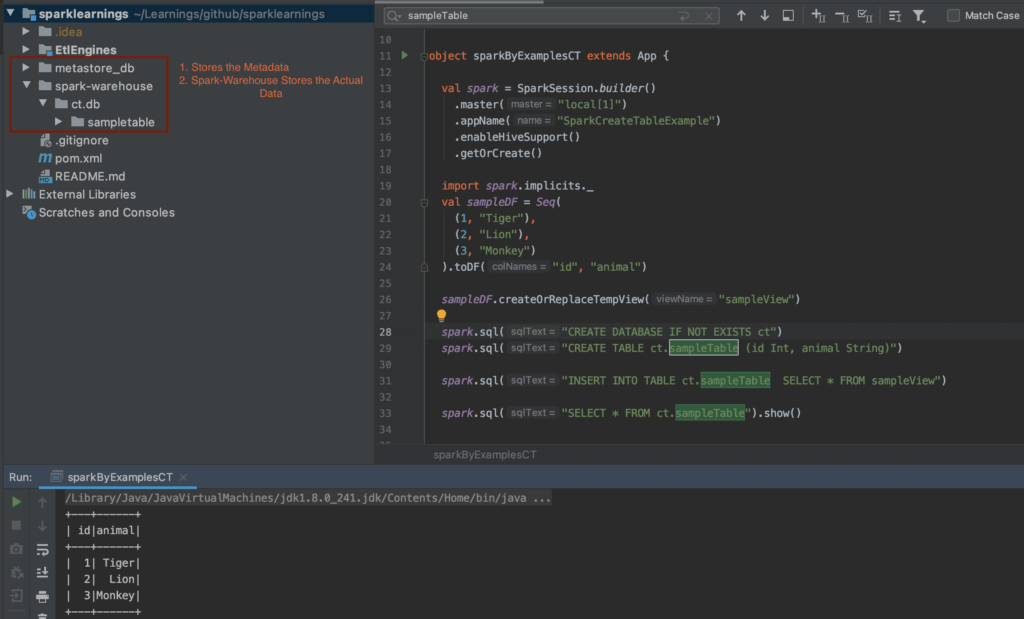
In the realm of Spark SQL, the `create table` statement takes on even greater flexibility. Spark SQL's ability to execute SQL queries against various data sources opens up a multitude of possibilities for table creation. For instance, the command `Spark.sql(drop table if exists + my_temp_table)` illustrates the ease with which tables can be dropped programmatically, clearing the way for new data structures. Similarly, `Spark.sql(create table mytable as select from my_temp_table)` demonstrates the powerful "create table as select" (CTAS) functionality, allowing you to create a new table directly from the results of a query. This CTAS approach is incredibly useful for creating summarized or filtered versions of existing datasets.
The `Createorreplacetempview` command introduces the concept of temporary tables, specifically those residing within the `global_temp` database. Temporary tables are session-scoped, meaning they exist only for the duration of the current Spark session. They are invaluable for intermediate calculations and data transformations within a larger data pipeline. Using `Createorreplacetempview` allows you to quickly define and manipulate temporary datasets without the overhead of creating persistent tables.
When working with temporary tables and performing CTAS operations, it's often necessary to specify the fully qualified name of the temporary table. For example, instead of `Create table mytable as select from my_temp_table`, it might be better to use `Create table mytable as select from global_temp.my_temp_table`. This ensures that Spark SQL correctly identifies the source table, especially when dealing with multiple databases and namespaces.
The statement, "Now that we have switched to the new database, we can create a table in it," underscores the importance of context when executing `create table` commands. Before creating a table, you must ensure that you are operating within the correct database. This can be achieved through commands like `USE database_name` in SQL or through Spark SQL's session configurations.
The basic code snippet `Spark.sql(create table if not exists mytable (id int, name string))` encapsulates the core elements of a `create table` statement in Spark SQL. The `create table if not exists` clause prevents errors if a table with the same name already exists. The statement then defines the table `mytable` with two columns: `id` (of type `int`) and `name` (of type `string`). This simple example highlights the fundamental structure of defining columns and their corresponding data types.
Understanding different file formats is crucial for effective table creation. The phrase, "Learn how to create a table using parquet file format in spark sql with examples and commands," emphasizes the importance of choosing the right storage format. Parquet, for instance, is a columnar storage format that excels at compressing data and accelerating query performance, particularly when dealing with large datasets and analytical workloads. Other formats, such as ORC and Avro, offer different trade-offs in terms of compression, schema evolution, and compatibility with various data processing tools. Choosing the optimal format depends on the specific requirements of your application.
The configuration setting `spark.sql.legacy.allownonemptylocationinctas` controls how Spark SQL handles the "location" attribute when creating tables using the CTAS approach. If set to `true`, Spark SQL will overwrite the underlying data source with the data resulting from the input query. This ensures that the newly created table contains exactly the same data as the query's output. However, this behavior can be destructive if the location already contains valuable data. Therefore, it's crucial to understand the implications of this setting before using CTAS with a specified location.
The statement, "It returns the dataframe associated with the table," refers to the result of querying a table in Spark SQL. When you execute a query like `SELECT FROM mytable`, Spark SQL returns a DataFrame, which is a distributed collection of data organized into named columns. This DataFrame can then be further processed using Spark's rich set of data manipulation and analysis functions.
The data source plays a pivotal role in table creation. "The data source is specified by the source and a set of options," highlights the flexibility of Spark SQL in accessing data from various sources. Spark SQL supports a wide range of data sources, including Parquet, ORC, CSV, JSON, JDBC databases, and cloud storage services like Amazon S3 and Azure Blob Storage. Each data source has its own set of options that control how Spark SQL connects to and reads data from the source.
"If source is not specified, the default data source configured by spark.sql.sources.default will be used," underscores the importance of understanding Spark SQL's default settings. If you don't explicitly specify the data source when creating a table, Spark SQL will use the data source defined by the `spark.sql.sources.default` configuration property. This property typically defaults to Parquet, but it can be changed to suit your specific needs.
"When path is specified, an external table is created from the data at the given path. Otherwise a managed table is created," this statement explains the crucial difference between managed and external tables. Managed tables are fully managed by Spark SQL, meaning Spark SQL controls both the data and the metadata. When you drop a managed table, both the data and the metadata are deleted. External tables, on the other hand, only have their metadata managed by Spark SQL. The data resides in an external location, such as a file system or cloud storage service. When you drop an external table, only the metadata is deleted; the data remains untouched in its external location.
The question, "Is it possible to create a table on spark using a select statement?" echoes the previous point about CTAS. The answer is a resounding yes! The CTAS functionality is a powerful tool for creating new tables directly from the results of SQL queries, enabling efficient data transformation and summarization.
The code snippet, "I do the following import findspark findspark.init() import pyspark from pyspark.sql import sqlcontext sc = pyspark.sparkcont," illustrates the typical setup required to use Spark SQL in a Python environment. The `findspark` library helps locate the Spark installation on your system. The `pyspark` library provides the Python API for interacting with Spark. The `sqlcontext` and `sparkcont` objects are essential for creating Spark SQL sessions and executing queries.
"This statement matches create table [using] using hive syntax. Create table [using] is preferred. Using this syntax you create a new table based on the definition, but not the data, of another table," this refers to creating a table with the schema of another table. You are essentially cloning the table's structure without copying the actual data. This is often useful when you want to create a new table with the same columns and data types as an existing table, but with a different name or storage location.
The phrase, "But it is not working," highlights the challenges that can arise when working with complex data systems like Spark and Hive. Debugging table creation issues often requires careful examination of error messages, configuration settings, and data source properties.
"It creates a table in hive with these properties : Create table default.test_partition ( id bigint, foo string ) with serdeproperties ('partitioncolumnnames'='id' the ddl of the table should actually be: Create table default.test_partition ( foo string ) partitioned by ( id bigint ) with serdeproperties (," This showcases a common pitfall when creating partitioned tables in Hive. The initial `create table` statement incorrectly includes the partition column (`id`) within the table's schema. The corrected DDL moves the `id` column to the `partitioned by` clause, indicating that the table is partitioned based on the values in the `id` column. Partitioning is a crucial optimization technique for improving query performance on large datasets, as it allows Hive to selectively read only the relevant partitions based on the query's filter conditions.
"Define schema for tables using structtype\u00b6 when we want to create a table using spark.catalog.createtable or using spark.catalog.createexternaltable, we need to specify schema. Schema can be inferred or we can pass schema using structtype object while creating the table. Structtype takes list of objects of type structfield," this describes how to explicitly define the schema of a table when using the Spark Catalog API. The `StructType` class provides a way to programmatically define the table's columns and their corresponding data types. This is particularly useful when the schema cannot be automatically inferred from the data source or when you want to enforce a specific schema on the table.
"However, the alteration you are trying to perform requires the table to be stored using an acid compliant format, such as orc," this highlights the importance of data format compatibility when performing certain table operations. ACID (Atomicity, Consistency, Isolation, Durability) properties ensure data integrity and reliability, especially in concurrent environments. Formats like ORC (Optimized Row Columnar) are often required for operations that involve transactional updates or modifications to table data.
"Try to create a new table with the tblproperties transactional set to true, deep copy into the new table the data from the first table, delete the first table and then rename the new table to the first table name," this outlines a strategy for migrating a non-ACID compliant table to an ACID-compliant format. The process involves creating a new table with the desired properties, copying the data from the original table, deleting the original table, and then renaming the new table to the original table's name. This ensures a seamless transition while preserving data integrity.
"Create table statement is used to define a table in an existing database. Create table using hive format," these statements reiterate the fundamental purpose and variations of the `create table` command.
"Specifies a table name, which may be optionally qualified with a database name," reinforces the point about database context and table naming conventions. Fully qualified table names (e.g., `database_name.table_name`) are often necessary to avoid ambiguity and ensure that Spark SQL correctly identifies the target table.
"Data source is the input format used to create the table," emphasizes the crucial role of the data source in table creation. The data source determines how Spark SQL reads and writes data to the table, and it can significantly impact the table's performance and storage characteristics.
"In this article, we shall discuss the types of tables and view available in apache spark & pyspark," this statement sets the scope of the discussion, highlighting the various types of tables and views that can be created in Spark SQL.
"To create your first iceberg table in spark, run a create table command. Let's create a table using demo.nyc.taxis where demo is the catalog name, nyc is the database name, and taxis is the table name," this introduces Iceberg, a modern table format designed for large-scale data warehousing. Iceberg offers features like schema evolution, time travel, and ACID transactions, making it a powerful alternative to traditional table formats.
"Iceberg will convert the column type in spark to corresponding iceberg type. Please check the section of type compatibility on creating table for details," this highlights the importance of understanding data type mappings when working with Iceberg tables. Iceberg has its own set of data types, and Spark SQL will automatically convert the column types to their corresponding Iceberg types during table creation. However, it's essential to verify that the data type mappings are correct and that they meet your application's requirements.
"Table create commands, including ctas and rtas, support the full range of spark create clauses, including:" This emphasizes the flexibility of Spark SQL's table creation commands, including CTAS (Create Table As Select) and RTAS (Replace Table As Select). These commands support a wide range of clauses, allowing you to customize the table's schema, storage format, partitioning, and other properties.
"From pyspark.sql import sparksession # create a sparksession spark = sparksession.builder.appname(managedandexternaltables).getorcreate() # create the managed table with the specified schema," This shows how to create a SparkSession, the entry point for using Spark SQL. The SparkSession is used to configure Spark, create DataFrames, and execute SQL queries.
"You cannot create external tables in locations that overlap with the location of managed tables," this is an important restriction to keep in mind when working with managed and external tables. Overlapping locations can lead to data corruption and unexpected behavior.
"For a delta lake table the table configuration is inherited from the location if data is present. Therefore, if any tblproperties , table_specification , or partitioned by clauses are specified for delta lake tables they must exactly match the delta," this highlights a specific behavior of Delta Lake tables, a popular open-source storage layer that provides ACID transactions and other features for data lakes. When creating a Delta Lake table, the table configuration is inherited from the underlying data if it already exists. This means that you cannot specify conflicting table properties or partitioning schemes.
"Before we dive deeper into the tables vs files folders, let\u2019s take a step back and explain two main table types in spark," This indicates a shift in focus towards the underlying storage mechanisms of Spark SQL tables.
"In case you missed it, spark is the compute engine for processing the data in the fabric lakehouse (opposite to polaris engine which handles sql workloads of the fabric warehouse)," This contextualizes Spark's role within a larger data ecosystem, specifically within the context of a data lakehouse architecture.
"Copy and paste the following code into an empty notebook cell. This code uses the apache spark filter method to create a new dataframe restricting the data by year, count, and sex. It uses the apache spark select() method to limit the columns. It also uses the apache spark orderby() and desc() functions to sort the new dataframe by count," This describes a sequence of data manipulation steps using Apache Spark's DataFrame API. These steps involve filtering, selecting, and sorting data within a DataFrame.
"One you can do it with spark.sql %python tables = [table1, table2] for table in tables: Spark.sql(f create table if not exists {table} using parquet location = '/mnt/{table}') or maybe with sql: Create table if not exists table1 using parquet location = '/mnt/${somelocation}' you can use widget for example to get somelocation:," This demonstrates how to programmatically create multiple tables in Spark SQL using a loop and string formatting. The example shows how to specify the table name, storage format (Parquet), and location using both Python and SQL syntax.
"Df_fact_sale = spark.read.table(wwilakehouse.fact_sale) df_dimension_date = spark.read.table(wwilakehouse.dimension_date) df_dimension_city = spark.read.table(wwilakehouse.dimension_city) add the following code to the same cell to join these tables using the dataframes created earlier," This shows how to read data from existing tables into DataFrames and then perform a join operation to combine the data.
"Group by to generate aggregation, rename a few of the," This indicates that the subsequent steps involve grouping data and renaming columns, common operations in data aggregation and analysis.
"A managed table is a spark sql table for which spark manages both the data and the metadata. In the case of a managed table, databricks stores the metadata and data in dbfs in your account. Since spark sql manages the tables, doing a drop table deletes both the metadata and data," This reiterates the definition of managed tables and their lifecycle. When dropping a managed table, both the metadata and the data are deleted, as Spark SQL has full control over both.
"I want to create another table based on the output of a select statement on this table as follows %spark.sql create table cleanusedcars as ( select (maker, model, mileage, manufacture_year, engine_displacement, engine_power, transmission, door_count, seat_count, fuel_type, date_created, date_last_seen, price_eur) from usedcars where maker is," This presents a practical scenario where the user wants to create a new table (`cleanusedcars`) based on a subset of data from an existing table (`usedcars`). The `create table as select` (CTAS) statement is used to achieve this.